Sailing is a thrilling and adventurous pastime that has captivated enthusiasts for centuries. For many sailors, the allure of being out on the open water, feeling the wind in their hair and the sun on their faces, is an unmatched experience. But there’s more to sailing than just enjoyment – there’s a valuable lesson in teamwork. This past Saturday, I had the pleasure of racing as part of a crew on a sailboat, and it reaffirmed my belief in the power of teamwork not just on the water, but everywhere.
The Essence of Teamwork in Sailing
Sailing a boat, especially during a race, is a complex and demanding task that requires the seamless coordination of multiple roles. From trimming the sails and adjusting the course to monitoring the weather conditions and making tactical decisions, every crew member plays a crucial role in the success of the journey.
When you’re part of a sailing crew, you quickly learn that no individual can single-handedly manage the boat. It takes a collective effort, with each person contributing their skills and knowledge, to navigate the vessel efficiently and safely. The importance of teamwork in sailing can be distilled into three key aspects: communication, trust, and collaboration.
Communication Clear and effective communication is the backbone of any successful sailing team. Crew members must constantly relay information to one another, from changes in wind direction to potential obstacles ahead. Timely and accurate communication is crucial in making quick decisions, especially when racing against other boats or dealing with unpredictable weather conditions. Good communication also helps to foster camaraderie, enabling the crew to work together more effectively.
Trust Sailing a boat at high speeds and in challenging conditions requires a tremendous amount of trust in your fellow crew members. You need to have confidence that each person will fulfill their role competently and that they will have your back when you need support. This trust is earned over time, through practice and experience, and it’s essential to the crew’s overall success.
Collaboration When a sailboat crew works together in harmony, the result is a finely-tuned machine. Each crew member must be aware of the others’ responsibilities and be prepared to step in and assist when necessary. This collaborative mindset is the key to overcoming challenges, adapting to changing conditions, and ultimately, winning races.
Being part of a sailboat crew has taught me the importance of teamwork in a way that few other experiences can. Out on the water, the stakes are high, and every decision counts. By fostering a strong team dynamic through communication, trust, and collaboration, a sailing crew can overcome obstacles, adapt to changing circumstances, and reach their destination successfully.
Whether you’re a seasoned worker or new to a workforce, never underestimate the power of teamwork. So, the next time you’re part of a team, remember to support one another, communicate openly, and work together – and you’ll find that success is smooth sailing.
Welcome back to MyTechStuff.site! In today’s post, we’ll explore the latest developments in cloud computing that are shaping the future of this fast-moving ICT industry. While cost optimization and security remain important considerations, we’ll focus on the exciting innovations and trends that are shaping up. Let’s dive in!
Serverless Computing
The rise of serverless computing is revolutionizing the way businesses build and deploy applications. By eliminating the need to manage server infrastructure, serverless computing enables developers to focus on writing code and delivering value to their customers. This innovative approach allows for faster development cycles, better resource utilization, and automatic scaling based on demand.
Multi-Cloud Strategies
As organizations seek to optimize their cloud investments and minimize vendor lock-in, multi-cloud strategies are becoming increasingly popular. By utilizing multiple cloud providers, businesses can leverage the unique strengths and capabilities of each platform, creating a more flexible and resilient cloud environment. This approach also allows organizations to distribute their workloads across multiple providers, ensuring data redundancy and reducing the risk of downtime.
AI and Machine Learning Integration
The integration of artificial intelligence (AI) and machine learning (ML) into cloud computing platforms is enabling businesses to unlock new insights and automate complex processes. These technologies can help organizations analyze large datasets, identify patterns, and make data-driven decisions. Additionally, AI and ML can optimize cloud resource usage, helping you to adjust allocations based on demand or actual utilization, and reducing overall costs.
Edge Computing
Edge computing is gaining traction as a complementary technology to traditional cloud computing. By processing data closer to the source, edge computing reduces latency and bandwidth requirements, improving the performance of data-intensive applications. This development is particularly important for Internet of Things (IoT) devices and real-time analytics, where low latency is crucial for optimal performance.
Enhanced Security and Cost Optimization
Although not the primary focus of this post, it’s worth mentioning that security and cost optimization continue to be essential aspects of cloud computing. As the industry evolves, providers are constantly developing new features and tools to help businesses protect their sensitive data and optimize their cloud investments.
Conclusion
The cloud computing landscape is constantly evolving, with new developments and innovations shaping the future of the industry. From serverless computing and multi-cloud strategies to AI integration and edge computing, these recent advancements are transforming the way businesses operate and opening up new possibilities. As cloud computing continues to mature, it’s crucial for organizations to stay informed about the latest trends and adapt their strategies accordingly.
Remember to keep an eye on security and cost optimization, as these aspects will always be relevant in the world of cloud computing. Stay tuned for future posts on MyTechStuff.site, where we’ll dive deeper into these exciting developments and explore their implications for businesses.
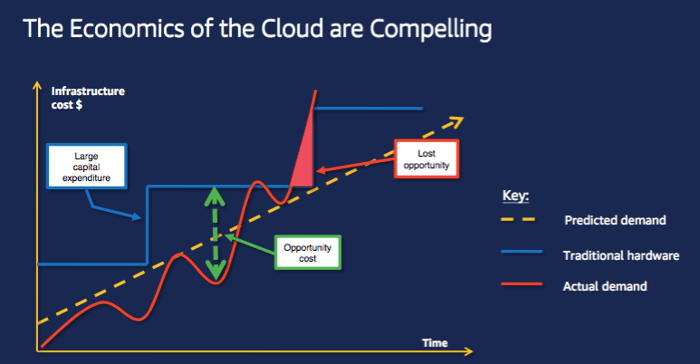
Benefits of Infrastructure-as-Code and Cloud Economics
As I see customers adopt Amazon Web Services, one of the first benefits they quickly realise is the ability to create and bootstrap environments at a time that suits them. This is a great benefit that helps to: (1) manage costs; and, (2) enable experimentation of new ideas. It appeals from both a financial perspective and an engineering perspective. With this foundational capability in hand, an organisation can build on it to gain further benefits. For example, accelerating product development to gain a competitive advantage.
Environments in Traditional Data Centres
In a traditional data centre we would typically see a dev | test | prod | dr type approach to defining non-production (development and test) and production (prod and disaster recovery) environments. The infrastructure for these environments would be purchased at a high cost. Then it would often be written down, for example over a typical 3-5 year hardware refresh cycle. Guesses would be made to estimate capacity in advance of equipment purchase, and proof-of-concept work would typically occur just-in-time of purchase. Proof-of-concept in a hardware refresh cycle might trial and prove new application architectures at that time, perhaps not to be revisited until the next refresh.
Environments in AWS Cloud
Thank goodness we’re no longer confined to traditional data centres! With Amazon Web Services, you can create infrastructure and services without paying any upfront purchase costs. You pay for what you use, when you use it. What’s more (and even better), when you are finished you can destroy the infrastructure and services you provisioned and no further costs are incurred. (Note of course I’m not suggesting you destroy your production environments here, but highlighting the lifecycle capability of provisioning environments in cloud).
Cloud providers such as Amazon Web Services have heralded changes that are nothing short of revolutionary. These changes contribute to the widely acknowledged current technological revolution – the Fourth Industrial Revolution. Globally we have seen the concept of cloud economics introduced to organisations and rapidly adopted. There’s now a more level playing field between smaller organisations and larger ones, which is accelerating innovation, disruptive ideas and products.
Underlying digital agility, innovation and productivity is IaC. Infrastructure-as-Code. IaC is a foundational capability of agile digital organisations. Using IaC you write the programming code to create your infrastructure and services. Once the code is written, the process is effectively automated.
Why use a human to do dumb, repetitive tasks? Automate them and boost your operational efficiency. Once you have your infrastructure code in hand, build a DevOps pipeline to manage the process of provisioning.
Humour me and imagine, if you will, some years in the not too distant future: you are part of a group putting your attention to understanding something. Somewhat like you might be doing now.
Boy on tin can phone listening to curious good news
Not everyone in your group is human.
We are not talking about alien life here. We’re not talking about animals either. No. Imagine for instance this particular fellow group member is an “intelligent agent”.
There are various definitions of an intelligent agent. For this case, let’s say that an intelligent agent is a device that perceives its environment and takes actions to maximise its chance of success.
An intelligent agent is a type of thing we more generally call artifical intelligence, or AI.
AI has arrived. What is AI?
AI and intelligent agents are changing the way we live and work.
Let’s think about this concept of intelligence. What is intelligence? Well, the Oxford dictionary defines it as “the ability to acquire and apply knowledge and skills”. Other definitions include: self-awareness, emotional knowledge, and capacity for logic. For our purpose of discussion, I’m going to define intelligence here as “the ability to achieve complex goals“. This definition broadly covers all of those ideas. There are many goals and the ability to achieve them provides a basis for intelligence.
Intelligence comes on a scale. The degree of ability to achieve a goal helps us understand where on the spectrum of intelligence something is. A complex goal might be: speaking. Let’s consider. Can a baby speak? No. Can an adult speak? Yes, generally. What about a child? All are somehwere different on the spectrum of intelligence.
Intelligence is narrow or broad. IBM’s Deep Blue chess computer beat the chess grandmaster Gary Kasparov in 1997. It could beat a chess grandmaster at chess but in noughts and crosses (a.k.a. tic-tac-toe), it couldn’t beat a 4-year old. It was built with a narrow focus of ability.
The more recent Google Deep Mind DQN AI system can play dozens of vintage Atari games at human level or better. This system is built to be able to apply itself to new goals. We might consier it has a broader capacity for intelligence.
Humans however, we as a species are so far unique in all the world with reagrd to intelligence. We are able to master a huge amount of skills. We can learn languages, sports, vocations and so much more. There’s nothing on the planet to rival us at this point in time.
General AI is coming
We are seeing accelerated breakthroughs and uses of AI in broader areas of our lives. Research and development in artificial intelligence has an endgame focus of general AI at a human level. Narrow AI will eventually evolve to become general AI. Whilst we do not know when this will happen (and some do question whether it will ever happen), there is no doubt of the advances and applications of AI.
Deep Mind has been able to learn many different games by using a positive reinforcement deep learning technique called reinforcement learning. This is a general unsupervised learning technique that computers use to teach themselves how to achieve narrow goals.
Using this technique, Google Deep Mind has been able to master and outplay human testers on 29 different vintage Atari games. Never sleeping, never resting and with no need to eat, computers can spend almost endless time learning how to achieve their goals in virtual reality, and then apply that knowledge when ready.
AlphaGo demonstrated strategic creatvity when it beat Lee Sedol, considered the top player of Go in the world in 2016. It was expected to take another decade before AI beat a human Go champion. AlphaGo went on to beat all 20 top players the year after it beat Lee Sedol.
AphaGo and Lee Sedol
To put this feat in context… there are many more possible Go positions than there are atoms in the entire universe. Therefore players rely heavily on intuition alongside conscious analysis. AlphaGo shocked the world by defying ancient wisdom by playing on the 5th line early in its 2nd game against Lee Sedol, and it went on to win the game. This was a demonstration of intuitive / creative play from a machine-based atrtifical intelligence.
AI is being widely used throughout our lives today
Natural language translation was not really considered possible when I studied AI back in the 1990s. As a student of computer science at university I recall discussing computation ability and we considered it as unable to cope with the ambiguities of natural langauge back then. Now we see natural language translation all around us. We are now seeing translation happen in real-time as well. What other examples do we see of AI all around us?
AI is being used in finance. Most stock market buy-sell decisions are now made automatically by computers. Algorithmic trading is the AI behind this. Algorithmic trading is used to help profitable trading. It allows resources to be efficiently allocated across the world at the speed of light.
In healthcare we are seeing changes in multiple areas, like diagnosis and surgery:
In 2015 a Dutch study showed that computer diagnosis of prostrate cancer using MRI was as good as human radiologists
In 2016 a Stanford study showed AI could diagnose lung cancer using microscope images better than human pathologists could
Machine learning is now used in medical research institutes such as Walter Eliza Hall Institute, for instance in predictive modelling for best outcomes based on analysis of genes, diseases and treatment responses
2 million robotic surgeries have been performed in the US smoothly between 2000 and 2013 according to a recent report in 2017
We are in the midst of the 4th industrial revolution. AI is one of the catalysts in this step change for humaity.
AI is now a permanent part of our lives, changing the way we live and work
Let’s review what we’ve covered.
Artificial Intelliegence has arrived. What is AI? It is a narrow, limited ability to achieve a goal, at this point time (2021). The engame is a broader, more capable ability to achieve complex goals.
General AI is coming. Accelerated breakthroughs have shown advancements in intuitive, creative, strategic mastery of games. Virtual reality is now commonly used for reinforcement learning in training AIs.
AI is widely used today for the positive benefit of human society. In finance and healthcare we are seeing improvements that benefit humans.
Imagine who’s listening
Imagine some time in the not too distant future, you’re part of a group putting your attention to understanding something. Not everyone in your group is human…
Amazon Virtual Private Cloud (VPC) is an abstract network service that allows you to create a virtual network of your own. Back when first introduced in 2009, it was a revolutionary concept that enabled the creation of a network of your very own – without you needing to own any IT hardware.
At present time of writing a VPC enables you to create a network address space using any IPv4 address range, including RFC 1918 or publicly routable IP ranges. The network can be between 16 and 65,536 IPv4 addresses in size. IPv6 is also supported.
The architecture of AWS Global Infrastructure means that your VPC spans multiple Availability Zones. It spans all Availability Zones in the AWS Region. Unlike many technology infrastructure providers, every AWS Region has 3 or more Availability Zones (AZ). AZs are geographically separated locations within an AWS region, connected by redundant fast fibre-optic data links.
Within your VPC, you define subnets in an Availability Zone. This means whilst your VPC spans all AZs, your subnets will not.
To manage and secure network traffic flow you use route tables. A VPC is created with a main route table. Each subnet you create must be associated with a custom route table or the main route table. The route table defines routing for your subnet, indicating how network data should flow.
To further secure your subnets, Network Access Control Lists (NACLs) can be defined. A NACL can be used to explicitly Allow or Deny network data to cross the boundary into or out of your subnet. Each subnet must be associated with a NACL – either the default NACL (provisioned when your VPC is first created) or a custom NACL.
One more security feature for capturing network traffic flows is VPC Flow Logs. This allows you to capture the traffic that flows to and from the network interfaces in your VPC or subnet.
There is much more to VPCs than this but these are the fundamentals. You can create an AWS account and create and destroy VPCs either through a management console or programmatically.
AWS PrivateLink is an interesting way to create an endpoint by which you can provide services to other AWS accounts. You can do this without the need to run requests through the Internet and without peering or otherwise “connecting” VPCs. What is this particular type of AWS magic, I hear you say?
Says the Amazon web site, “AWS PrivateLink provides private connectivity between VPCs and services hosted on AWS or on-premises, securely on the Amazon network. By providing a private endpoint to access your services, AWS PrivateLink ensures your traffic is not exposed to the public internet. AWS PrivateLink makes it easy to connect services across different accounts and VPCs to significantly simplify your network architecture.”
So this is a particularly interesting AWS magic trick in that we can provide services to other consumer VPCs, through the Amazon backbone. We simply do two things to make his happen:
Create an Endpoint Service, in our serivce provider VPC
Create an Interface Endpoint (linked to our Endpoint Service), in our service consumer VPC
Where this gets really interesting is that it avoids all the unruliness of network address spaces and having to deal with Network Address Tranlsation (NAT). Routing works through a network interface to the endpoint service and you don’t have to worry about the network addresses. And if the endpoint service is unavailable in one Availability Zone, well that’s not a problem because your endpoint service will load balance across multiple Availability Zones.
Not to put too finer point on it, but to get the engineering and provisioning underlying all that without lifting a finger? That’s a kind of magic.
In my last blog, I mentioned a basic Web App that I had put together using Visual Studio 2015 tooling for .NET Core. Over the last couple of days, I’ve been looking at publishing the App, and the steps involved.
.NET Core is a new beast with a lot of potential…. the aim is it will run anywhere, on anything. So to keep my costs down, I’m going to trial it on my Amazon Linux VM. Note to self, SQL Server for Linux is about 1 year down the track – unfortunate, as the MVC scaffold uses SQL Server LocalDB – so I’ll have to figure out what database I can use.
But, first things first… how to publish my App to Linux?
First step – publish the App using dotnet publish. I found that Bower was not referenced in my Path environment variable. Bower was installed with Visual Studio 2015 Professional – in a sub-folder of my Visual Studio 2015 folder. I’m not sure if it was installed because I had installed tooling for .NET Core, or if it comes by default. Anyway, once that was sorted, dotnet publish worked fine and it created a portable for me to use.
I copied all of the files in the folder that dotnet publish created over to my Amazon Linux server. (I used WinSCP for this). Then I found I needed to install .NET Core on Amazon Linux. Installation was easy but when I tried to run the dotnet CLI, I received an error. Running dotnet –info from a bash shell I saw,
dotnet: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.18′ not found (required by dotnet)
After several hours of searching, I found this was due to the libstdc++ library version on my Amazon Linux distribution, which was libstdc++47. I had ensured my VM was up to date, so it seems that the libstc++ version was lagging (for whatever reason). After running the below, I was able to successfully run the dotnet CLI, with a valid response from dotnet –info.
sudo yum install libstdc++48
So, I had installed .NET core and fixed up the reference library it needed. After that, I needed a way to access my Web App. Kestrel is a web server built into .NET Core and can listen on any port you tell it to. However, it is better to use a web server as a proxy/reverse-proxy to relay request/response to Kestrel.
I already had a web server on my Amazon Linux VM. So I configured it with proxy and reverse-proxy mappings (to the Kestrel server in my .NET Core App). The calls to my web server forward on to the Kestrel server in the App, and vice-versa. I ran the App with dotnet run and checked access via the web server. All good 🙂
Almost there.
Finally, I installed supervisor to manage start/stop/restart of my App. And set up a script to ensure supervisor is re-started whenever my Amazon Linux machine restarts.
Note, this would have taken days if not for the early groundwork of several people who blog their efforts.
Now I have a Web App but no database. So next step is to get the database up and running.
Over the past couple of weeks, I’ve spent some time drafting a Web App for Touch Footy results. The App is built on .NET Core, and this gave me a great opportunity to review the new Visual Studio .NET Core tooling. But once I had my bare bones App, I needed some data to play with. Enter Scrapy and Python…
What I wanted was a data set that I could use in the Touch Footy App. I had a good data source and I figured my best bet was a web scraper. Scrapy made it easy for me to scrape together my test data set. It’s built using Python (hence you need some understanding of Python to use it). Python is an interpreted language. It’s great for list processing and it’s easy to read/write.
Scrapy is an open source framework for writing web crawlers, or spiders. It gives you control over how and when you execute the spiders you’ve written. And a great shell as a part of the framework to test/debug commands. After looking at other web scraping options, I decided on Scrapy as a neat way to get my data.
After a few hours coding, I had a crawler that collected the data I wanted, i.e. groups, teams, fixtures and results for my Web App. I wanted to store the data in JSON – for easy processing – and Scrapy made that easy too. It was simple then to write some Python code to process the JSON for groups, teams, fixtures and results.
All good so far, and fun to boot. My next step – how to get the data to the Touch Footy Web App? Well, Visual Studio 2015 tooling for .NET Core makes it easy to add a Web API to an MVC Web Application…. several hours later I had a working spider populating data into my App.
It’s been a long time coming, but I have a feeling that the Cloud is about to get real. For everybody.
Google had a good offering for a while, and Adobe have a small corner of the market. But, Microsoft have been busy. They are on board, and they have turned a corner.
Microsoft Office 365 is now a fully-operational cloud offering. Office 365 works on all devices. For example, iPhone, Galaxy, Nexus, iPad, MacBook, Laptop etc.
What this means is that you can use Outlook, Word, Excel, PowerPoint. Anywhere, anytime on anything. Because not only do you get those applications… you also get a cloud file system, Sharepoint.
To be honest, I think this has the potential to create a step change in the way people work and live. That’s a bold statement but, frankly, all previous offerings pale in comparison to what Office 365 offers.
The world’s not spinning any faster… but working in IT these days sees my thoughts spinning faster than ever. I’m a career IT guy and I have to stay on top of this stuff. Not just for my career, but it’s just who I am. It’s in my DNA.
I’ve done this tech stuff for a long time, and I’m pretty quick on the uptake. But it’s getting crazy out there. The rate of tech advance increases day by day, creating new or deeper specializations over time. It’s a time-consuming effort to maintain the general knowledge to manage IT well.
Mind you, that general knowledge is actually highly specialized tech knowledge. And very valuable it is too. So, in an effort to make it more accessible for myself, I’m gong to start writing down my thoughts. Maybe even organizing them.
And perhaps they will be useful not just for me. So here we go…